











C++ sans *pointeurs
Les pointeurs sont utilisés plus souvent que nécessaire en C++.
Je voudrais présenter ici comment caractériser les utilisations abusives et par quoi les remplacer.
Objectifs
La décision d’utiliser des pointeurs dépend en grande partie de l’API des objets utilisés.
API est à comprendre dans un sens très large : je considère que des classes utilisées dans une autre partie d’une même application exposent une API.
L’objectif est donc de concevoir des API de manière à ce que leur utilisation ne nécessite pas de manipuler de pointeurs, ni même si possible de smart pointers.
Cela peut paraître surprenant, mais c’est en fait ainsi que vous utilisez les classes de la STL ou de Qt : vos méthodes ne retournent jamais un raw pointer ni un smart pointer vers une string nouvellement créée.
De manière générale, vous n’écririez pas ceci :
// STL version
string *getName() {
return new string("my name");
}
// Qt version
QString *getName() {
return new QString("my name");
}ni ceci :
// STL version
shared_ptr<string> getName() {
return make_shared<string>("my name");
}
// Qt version
QSharedPointer<QString> getName() {
return QSharedPointer<QString>::create("my name");
}À la place, vous écririez sûrement :
// STL version
string getName() {
return "my name";
}
// Qt version
QString getName() {
return "my name";
}Notre objectif est d’écrire des classes qui s’utiliseront de la même manière.
Ownership
Il faut distinguer deux types de raw pointers :
- ceux qui détiennent l’objet pointé (owning), qui devront être libérés ;
- ceux qui ne le détiennent pas (non-owning).
Le plus simple est de les comparer sur un exemple.
Owning
Info *getInfo() {
return new Info(/* … */);
}
void doSomething() {
Info *info = getInfo();
// info must be deleted
}Ici, nous avons la responsabilité de supprimer info au bon moment.
C’est ce type de pointeurs dont nous voulons nous débarrasser.
Non-owning
void writeDataTo(QBuffer *buffer) {
buffer->write("c++");
}
void doSomething() {
QBuffer buffer;
writeDataTo(&buffer);
}Ici, le pointeur permet juste de passer l’adresse de l’objet, mais la méthode
writeDataTo(…) ne doit pas gérer sa durée de vie : elle ne le détient donc
pas.
Cet usage est tout-à-fait légitime, nous souhaitons le conserver.
Pour savoir si un pointeur est owning ou non, il suffit de se poser la
question suivante : est-ce que lui affecter nullptr provoquerait une fuite
mémoire ?
Pourquoi ?
Voici quelques exemples illustrant pourquoi nous voulons éviter les owning raw pointers.
Fuite mémoire
Il est facile d’oublier de supprimer un pointeur dans des cas particuliers.
Par exemple :
bool parse() {
Parser *parser = createParser();
QFile file("file.txt");
if (!file.open(QIODevice::ReadOnly))
return false;
bool result = parser->parse(&file);
delete parser;
return result;
// parser leaked if open failed
}Ici, si l’ouverture du fichier a échoué, parser ne sera jamais libéré.
L’exemple suivant est encore plus significatif :
Result *execute() {
// …
return new Result(/* … */);
}
void doWork() {
execute();
// result leaked
}Appeler une méthode sans s’occuper du résultat peut provoquer des fuites mémoires.
Double suppression
Il est également possible, par inattention, de supprimer plusieurs fois le même pointeur (ce qui entraîne un undefined behavior).
Par exemple, si device fait partie de la liste devices, ce code le supprime
deux fois :
delete device;
qDeleteAll(devices);
// device is deleted twiceUtilisation après suppression
L’utilisation d’un pointeur après sa suppression est également indéfinie.
Je vais prendre un exemple réel en Qt.
Supposons qu’une classe DeviceMonitor surveille le branchement de
périphériques, et crée pour chacun un objet Device.
Lorsqu’un périphérique est débranché, un signal Qt provoque
l’exécution du slot DeviceMonitor::onDeviceLeft(Device *). Nous voulons
alors signaler au reste de l’application que le device est parti (signal
DeviceMonitor::deviceLeft(Device *)), puis supprimer l’object device
correspondant :
void DeviceMonitor::onDeviceLeft(Device *device) {
emit deviceLeft(device);
delete device;
// slots may use the device after its deletion
// device->deleteLater() not sufficient
}Mais c’est loin d’être trivial.
Si nous le supprimons immédiatement comme ceci, et qu’un slot est branché à
DeviceMonitor::deviceLeft(Device *) en
Qt::QueuedConnection, alors il est possible que le pointeur
soit déjà supprimé quand ce slot sera exécuté.
Un proverbe dit que quand ça crashe avec un delete, “il faut appeller
deleteLater() pour corriger le problème” :
device->deleteLater();Mais malheureusement, ici, c’est faux : si le slot branché au signal
DeviceMonitor::deviceLeft(Device *) est associé à un QObject
vivant dans un autre thread, rien ne garantit que son
exécution aura lieu avant la suppression du pointeur.
L’utilisation des owning raw pointers n’est donc pas seulement vulnérable aux erreurs d’inattention (comme dans les exemples précédents) : dans des cas plus complexes, il devient difficile de déterminer quand supprimer le pointeur.
Responsabilité
De manière plus générale, lorsque nous avons un pointeur, nous ne savons pas forcément qui a la responsabilité de le supprimer, ni comment le supprimer :
Data *data = getSomeData();
delete data; // ?
free(data); // ?
custom_deleter(data); // ?Qt fournit un mécanisme pour supprimer automatiquement les QObject * quand
leur parent est détruit. Cependant, cette fonctionnalité ne s’applique qu’aux
relations de composition.
Résumons les inconvénients des owning raw pointeurs :
- la gestion mémoire est manuelle ;
- leur utilisation est propice aux erreurs ;
- la responsabilité de suppression n’est pas apparente ;
- déterminer quand supprimer le pointeur peut être difficile.
Valeurs
Laissons de côté les pointeurs quelques instants pour observer ce qu’il se passe avec de simples valeurs (des objets plutôt que des pointeurs vers des objets) :
struct Vector {
int x, y, z;
};
Vector transform(const Vector &v) {
return { -v.x, v.z, v.y };
}
void compute() {
Vector vector = transform({ 1, 2, 3 });
emit finished(transform(vector));
}C’est plus simple : la gestion mémoire est automatique, et le code est plus sûr. Par exemple, les fuites mémoire et les double suppressions sont impossibles.
Ce sont des avantages dont nous souhaiterions bénéficier également pour les pointeurs.
Privilégier les valeurs
Dans les cas où les pointeurs sont utilisés uniquement pour éviter de retourner des copies (et non pour partager des objets), il est préférable de retourner les objets par valeur à la place.
Par exemple, si vous avez une classe :
struct Result {
QString message;
int code;
};Évitez :
Result *execute() {
// …
return new Result { message, code };
}Préférez :
Result execute() {
// …
return { message, code };
}Certes, dans certains cas, il est moins efficace de passer un objet par valeur qu’à travers un pointeur (car il faut le copier).
Mais cette inefficacité est à relativiser.
D’abord parce que dans certains cas (quand l’objet est copié à partir d’une
rvalue reference), la copie sera remplacée par un move. Le move
d’un vector par exemple n’entraîne aucune copie (ni move) de ses
éléments.
Ensuite parce que les compilateurs optimisent le retour par valeur
(RVO), ce qui fait qu’en réalité dans les exemples ci-dessus, aucun Result
ni Vector n’est jamais copié ni mové : ils sont directement créés à
l’endroit où ils sont affectés (sauf si vous compilez avec le paramètre
-fno-elide-constructors).
Mais évidemment, il y a des cas où nous ne pouvons pas simplement remplacer un pointeur par une valeur, par exemple quand un même objet doit être partagé entre différentes parties d’un programme.
Nous voudrions les avantages des valeurs également pour ces cas-là. C’est l’objectif de la suite du billet.
Idiomes C++
Pour y parvenir, nous avons besoin de faire un détour par quelques idiomes couramment utilisés en C++.
Ils ont souvent un nom étrange. Par exemple :
- RAII (Resource Acquisition Is Initialization)
- PIMPL (Pointer to IMPLementation)
- CRTP (Curiously Recurring Template Pattern)
- SFINAE (Substitution Failure Is Not An Error)
- IIFE (Immediately-Invoked Function Expression)
Nous allons étudier les deux premiers.
RAII
Prenons un exemple simple :
bool submit() {
if (!validate())
return false;
return something();
}Nous souhaitons rendre cette méthode thread-safe grâce à un mutex
(std::mutex en STL ou QMutex en Qt).
Supposons que validate() et something() puissent lever une exception.
Le mutex doit être déverrouillé à la fin de l’exécution de la méthode. Le problème, c’est que cela peut se produire à différents endroits, donc nous devons gérer tous les cas :
bool submit() {
mutex.lock();
try {
if (!validate()) {
mutex.unlock();
return false;
}
bool result = something();
mutex.unlock();
return result;
} catch (...) {
mutex.unlock();
throw;
}
}Le code est beaucoup plus complexe et propice aux erreurs.
Avec des classes utilisant RAII (std::lock_guard en STL ou
QMutexLocker en Qt), c’est beaucoup plus simple :
bool submit() {
QMutexLocker locker(&mutex);
if (!validate())
return false;
return something();
}En ajoutant une seule ligne, la méthode est devenue thread-safe.
Cette technique consiste à utiliser le cycle de vie d’un objet pour acquérir une ressource dans le constructeur (ici verrouiller le mutex) et la relâcher dans le destructeur (ici le déverrouiller).
Voici une implémentation simplifiée possible de QMutexLocker :
class QMutexLocker {
QMutex *mutex;
public:
explicit QMutexLocker(QMutex *mutex) : mutex(mutex) {
mutex->lock();
}
~QMutexLocker() {
mutex->unlock();
}
};Comme l’objet est détruit lors de la sortie du scope de la méthode (que ce
soit par un return ou par une exception survenue n’importe où), le mutex
sera toujours déverrouillé.
Au passage, dans l’exemple ci-dessus, nous remarquons que la variable locker
n’est jamais utilisée. RAII complexifie donc la détection des variables
inutilisées, car le compilateur doit détecter les effets de bords. Mais il s’en
sort bien : ici, il n’émet pas de warning.
Smart pointers
Les smart pointers utilisent RAII pour gérer automatiquement la durée de vie des pointeurs. Il en existe plusieurs.
Dans la STL :
std::unique_ptrstd::shared_ptrstd::weak_ptrstd::auto_ptr(à bannir)
Dans Qt :
QSharedPointer(équivalent destd::shared_ptr)QWeakPointer(équivalent destd::weak_ptr)QScopedPointer(ersatz destd::unique_ptr)QScopedArrayPointerQPointerQSharedDataPointerQExplicitlySharedDataPointer
Scoped pointers
Le smart pointer le plus simple est le scoped pointer. L’idée est vraiment
la même que QMutexLocker, sauf qu’au lieu de vérouiller et
déverrouiller un mutex, il stocke un raw pointer et le supprime.
En plus de cela, comme tous les smart pointers, il redéfinit certains opérateurs pour pouvoir être utilisé comme un raw pointer.
Par exemple, voici une implémentation simplifiée possible de
QScopedPointer :
template <typename T>
class QScopedPointer {
T *p;
public:
explicit QScopedPointer(T *p) : p(p) {}
~QScopedPointer() { delete p; }
T *data() const { return p; }
operator bool() const { return p; }
T &operator*() const { return *p; }
T *operator->() const { return p; }
private:
Q_DISABLE_COPY(QScopedPointer)
};Et un exemple d’utilisation :
// bad design (owning raw pointer)
DeviceInfo *Device::getDeviceInfo() {
return new DeviceInfo(/* … */);
}
void Device::printInfo() {
QScopedPointer<DeviceInfo> info(getDeviceInfo());
// used like a raw pointer
if (info) {
qDebug() << info->getId();
DeviceInfo copy = *info;
}
// automatically deleted
}Shared pointers
Les shared pointers permettent de partager l’ownership (la responsabilité de suppression) d’une ressource.
Ils contiennent un compteur de références, indiquant le nombre d’instances partageant le même pointeur. Lorsque ce compteur tombe à 0, le pointeur est supprimé (il faut donc éviter les cycles).
En pratique, voici ce à quoi ressemblerait une liste de Devices partagés par
des QSharedPointers :
class DeviceList {
QList<QSharedPointer<Device>> devices;
public:
QSharedPointer<Device> getDevice(int index) const;
void add(const QSharedPointer<Device> &device);
void remove(Device *device);
};
// devices are automatically deleted when necessaryLe partage d’un pointeur découle toujours de la copie d’un shared pointer.
C’est la raison pour laquelle getDevice(…) et add(…) manipulent un
QSharedPointer.
Le piège à éviter est de créér plusieurs smart pointers indépendants sur le même raw pointer. Dans ce cas, il y aurait deux refcounts à 1 plutôt qu’un refcount à 2, et le pointeur serait supprimé dès la destruction du premier shared pointer, laissant l’autre pendouillant.
Petite parenthèse : la signature des méthodes add et remove sont
différentes car une suppression ne nécessite pas de manipuler la durée de
vie du Device passé en paramètre.
Refcounted smart pointers are about managing te owned object’s lifetime.
Copy/assign one only when you intend to manipulate the owned object’s lifetime.
Au passage, si en Qt vous passez vos objets de la couche C++ à la couche QML, il faut aussi passer les shared pointers afin de ne pas casser le partage, ce qui implique d’enregistrer le type :
void registerQml() {
qRegisterMetaType<QSharedPointer<Device>>();
}Listons donc les avantages des shared pointers :
- la gestion mémoire est automatique ;
- l’ownership est géré automatiquement ;
- l’utilisation est moins propice aux erreurs (à part la possibilité de créer des smart pointers indépendants sur le même raw pointer) ;
Cependant, si la gestion mémoire est automatique, elle n’est pas
transparente : elle nécessite de manipuler explicitement des
QSharedPointer, ce qui est verbeux.
Il est certes possible d’utiliser un alias (typedef) pour atténuer la verbosité :
using DevicePtr = QSharedPointer<Device>;
class DeviceList {
QList<DevicePtr> devices;
public:
DevicePtr getDevice(int index) const;
void add(const DevicePtr &device);
void remove(Device *device);
};Mais quoi qu’il en soit, cela reste plus complexe que des valeurs.
Pour aller plus loin, nous allons devoir faire un détour inattendu, par un idiome qui n’a a priori rien à voir.
PImpl
PImpl sert à réduire les dépendances de compilation.
Opaque pointers are a way to hide the implementation details of an interface from ordinary clients, so that the implementation may be changed without the need to recompile the modules using it.
Prenons la classe Person suivante (person.h) :
class Person {
QString name;
long birth;
public:
Person(const QString &name, long birth);
QString getName() const;
void setName(const QString &name);
int getAge() const;
private:
static long countYears(long from, long to);
};Elle contient juste un nom et un âge. Elle définit par ailleurs une méthode
privée, countYears(…), qu’on imagine appelée dans getAge().
Chaque classe désirant utiliser la classe Person devra l’inclure :
#include "person.h"Par conséquent, à chaque modification de ces parties privées (qui sont pourtant
que des détails d’implémentation), toutes les classes incluant person.h
devront être recompilées.
C’est ce que PImpl permet d’éviter, en séparant la classe en deux :
- une interface publique ;
- une implémentation privée.
Concrètement, la classe Person précédente est la partie privée. Renommons-la :
class PersonPrivate {
QString name;
long birth;
public:
PersonPrivate(const QString &name, long birth);
QString getName() const;
void setName(const QString &name);
int getAge() const;
private:
static long countYears(long from, long to);
};Créons la partie publique, définissant l’interface souhaitée :
class PersonPrivate; // forward declaration
class Person {
PersonPrivate *d;
public:
Person(const QString &name, long birth);
Person(const Person &other);
~Person();
Person &operator=(const Person &other);
QString getName() const;
void setName(const QString &name);
int getAge() const;
};Elle contient un pointeur vers PersonPrivate, et lui délègue tous les appels.
Évidemment, Person ne doit pas inclure PersonPrivate, sinon nous aurions les
mêmes dépendances de compilation, et nous n’aurions rien résolu. Il faut
utiliser à la place une forward declaration.
Voici son implémentation :
Person::Person(const QString &name, long birth) :
d(new PersonPrivate(name, birth)) {}
Person::Person(const Person &other) :
d(new PersonPrivate(*other.d)) {}
Person::~Person() { delete d; }
Person &Person::operator=(const Person &other) {
*d = *other.d;
return *this;
}
QString Person::getName() const {
return d->getName();
}
void Person::setName(const QString &name) {
d->setName(name);
}
int Person::getAge() const {
return d->getAge();
}Le pointeur vers la classe privée est souvent nommé d car il s’agit d’un
d-pointer.
Donc comme prévu, tout cela n’a rien à voir avec notre objectif d’éviter d’utiliser des pointeurs.
Partage
Mais en fait, si. PImpl permet de séparer les classes manipulées explicitement de l’objet réellement modifié :

Il y a une relation 1-1 entre la classe publique et la classe privée correspondante. Mais nous pouvons imaginer d’autres cardinalités.
Par exemple, Qt partage implicitement les parties privées d’un grand nombre de classes. Il ne les copie que lors d’une écriture (CoW) :
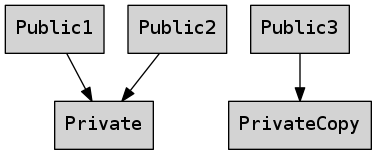
Par exemple, lorsqu’une QString est copiée, la même zone mémoire
sera utilisée pour les différentes instances, jusqu’à ce qu’une modification
survienne.
Cependant, il ne s’agit que d’un détail d’implémentation utilisé pour améliorer les performances. Du point de vue utilisateur, tout se passe comme si les données étaient réellement copiées :
QString s1 = "ABC";
QString s2 = s1;
s2.append("DEF");
Q_ASSERT(s2 == "ABCDEF");
Q_ASSERT(s1 == "ABC");En d’autres termes, les classes publiques ci-dessus ont une sémantique de valeur.
Resource handles
À la place, nous pouvons décider de partager inconditionnellement la partie privée, y compris après une écriture :
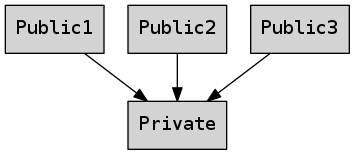
Dans ce cas, la classe publique a sémantique d’entité. Elle est qualifiée de resource handle.
C’est bien sûr le cas des smart pointers :
QSharedPointer<Person> p1(new Person("ABC", 42));
QSharedPointer<person> p2 = p1;
p2->setName("DEF");
Q_ASSERT(p1.getName() == "DEF");
Q_ASSERT(p2.getName() == "DEF");Mais aussi d’autres classes, comme l’API Dom de Qt :
void addItem(const QDomDocument &document, const QDomElement &element) {
QDomElement root = document.documentElement();
root.insertAfter(element, {});
// the document is modified
}PImpl avec des smart pointers
Tout-à-l’heure, j’ai présenté PImpl en utilisant un owning raw pointer :
class PersonPrivate; // forward declaration
class Person {
// this is a raw pointer!
PersonPrivate *d;
public:
// …
};Mais en fait, à chaque type de relation correspond un type de smart pointer directement utilisable pour PImpl.
Pour une relation 1-1 classique :
Pour une relation 1-N à sémantique de valeur (CoW) :
Pour une relation 1-N à sémantique d’entité :
Par exemple, donnons à notre classe Person une sémantique d’entité :
class PersonPrivate; // forward declaration
class Person {
QSharedPointer<PersonPrivate> d;
public:
Person() = default; // a "null" person
Person(const QString &name, long birth);
QString getName() const;
// shared handles should expose const methods
void setName(const QString &name) const;
int getAge() const;
operator bool() const { return d; }
};Person se comporte maintenant comme un pointeur.
Person p1("ABC", 42);
Person p2 = p1;
p2.setName("DEF");
Q_ASSERT(p1.getName() == "DEF");
Q_ASSERT(p2.getName() == "DEF");p1 et p2 sont alors des resource handles vers PersonPrivate :
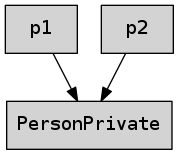
Évidemment, ce n’est pas approprié pour la classe Person, car le comportement
est trop inattendu.
Mais je vais présenter un cas réel où ce design est approprié.
En pratique
Pour l’entreprise dans laquelle je suis salarié, j’ai implémenté une fonctionnalité permettant d’utiliser une souris USB branchée sur un PC pour contrôler un téléphone Android connecté en USB.
Concrètement, cela consiste à tranférer (grâce à libusb), à partir
du PC, les événements HID reçus de la souris vers le téléphone Android.
J’ai donc (entre autres) créé des resources handles UsbDevice et
UsbDeviceHandle qui wrappent les structures C libusb_device
et libusb_device_handle, suivant les principes
détaillés dans ce billet.
Leur utilisation illustre bien, d’après moi, les bénéfices d’une telle conception.
class UsbDeviceMonitor {
QList<UsbDevice> devices;
public:
// …
UsbDevice getAnyDroid() const;
UsbDevice getAnyMouse() const;
signals:
void deviceArrived(const UsbDevice &device);
void deviceLeft(const UsbDevice &device);
};UsbDevice peut être retourné par valeur, et passé en paramètre d’un signal
par const reference (exactement comme nous le ferions avec un
QString).
UsbDevice UsbDeviceMonitor::getAnyMouse() const {
for (const UsbDevice &device : devices)
if (device.isMouse())
return device;
return {};
}Si une souris est trouvée dans la liste, on la retourne simplement ; sinon, on
retourne un UsbDevice “null”.
void UsbDeviceMonitor::onHotplugDeviceArrived(const UsbDevice &device) {
devices.append(device);
emit deviceArrived(device);
}La gestion mémoire est totalement automatique et transparente. Les problèmes présentés sont résolus.
void registerQml() {
qRegisterMetaType<UsbDevice>();
}// QML
function startForwarding() {
var mouse = usbDeviceMonitor.getAnyMouse()
var droid = usbDeviceMonitor.getAnyDroid()
worker = hid.forward(mouse, droid)
}UsbDevice peut naviguer entre la couche C++ et QML.
bool HID::forward(const UsbDevice &mouse, const UsbDevice &droid) {
UsbDeviceHandle droidHandle = droid.open();
if (!droidHandle)
return false;
UsbDeviceHandle mouseHandle = mouse.open();
if (!mouseHandle)
return false;
// …
}Grâce à RAII, les connexions (UsbDeviceHandle) sont fermées automatiquement.
En particulier, si la connexion à la souris échoue, la connexion au téléphone Android est automatiquement fermée.
Résultat
Dans ces différents exemples, new et delete ne sont jamais utilisés, et
par construction, la mémoire sera correctement gérée. Ou plus précisément,
si un problème de gestion mémoire existe, il se situera dans l’implémentation de
la classe elle-même, et non partout où elle est utilisée.
Ainsi, nous manipulons des handles se comportant comme des pointeurs, ayant les mêmes avantages que les valeurs :
- gestion mémoire automatique et transparente ;
- simple ;
- efficace ;
- sûr et robuste.
Ils peuvent par contre présenter quelques limitations.
Par exemple, ils sont incompatibles avec QObject. En effet,
techniquement, la classe d’un resource handle doit pouvoir être copiée (pour
supporter le passage par valeur), alors qu’un QObject n’est pas
copiable :
QObjects are identities, not values.
Très concrètement, cela implique que UsbDevice ne pourrait pas supporter de
signaux (en tout cas, pas directement). C’est d’ailleurs le cas de beaucoup de
classes de Qt : par exemple QString et QList n’héritent
pas de QObject.
Résumé
auto decide = [=] {
if (semantics == VALUE) {
if (!mustAvoidCopies)
return "just use values";
return "use PImpl + QSharedDataPointer";
}
// semantics == ENTITY
if (entitySemanticsIsObvious)
return "use PImpl + QSharedPointer";
return "use smart pointers explicitly";
};C’est juste une heuristique…
Conclusion
En suivant ces principes, nous pouvons nous débarrasser des owning
raw pointers et des new et delete “nus”. Cela contribue à rendre le code
plus simple et plus robuste.
Ce sont d’ailleurs des objectifs qui guident les évolutions du langage C++ :
- A brief introduction to C++’s model for type and resource-safety
- Writing good C++14
- Elements of Modern C++ Style
return 0;

