











htop expliqué, partie 1 : l’uptime
Avec l’accord de Pēteris Ņikiforovs, auteur original de l’excellent article htop explained : Explanation of everything you can see in htop/top on Linux (1er sur Hacker News, 1er sur /r/sysadmin, 2nd sur /r/linux), j’entreprends une série d’articles visant à traduire en français son excellente explication de htop et des notions de base d’un système GNU/Linux présentées par ce programme.
L’approche didactique m’est apparue excellente et me semble pouvoir être d’une grande aide à toutes les personnes intéressées par ce qui se passe sur leur système GNU/Linux. Une traduction en français s’imposait donc 
Aujourd’hui : l’uptime.
htop expliqué
Explication de tout ce que vous pouvez voir dans htop/top sur Linux
Bien longtemps je n’ai pas su ce que toutes les valeurs dans htop signifiaient.
Je pensais qu’un load average de 1.0 sur ma machine à deux coeurs signifiait que l’utilisation CPU était de 50%. Ce n’est pas tout à fait vrai. Et entre autre, pourquoi 1.0 ?
J’ai alors décidé de tout chercher et de le documenter ici.
Il est aussi dit que le meilleur moyen d’apprendre quelque chose est de tenter de l’enseigner.
htop sur Ubuntu Server 16.04 x64
Voici une copie d’écran de htop que je vais décrire.
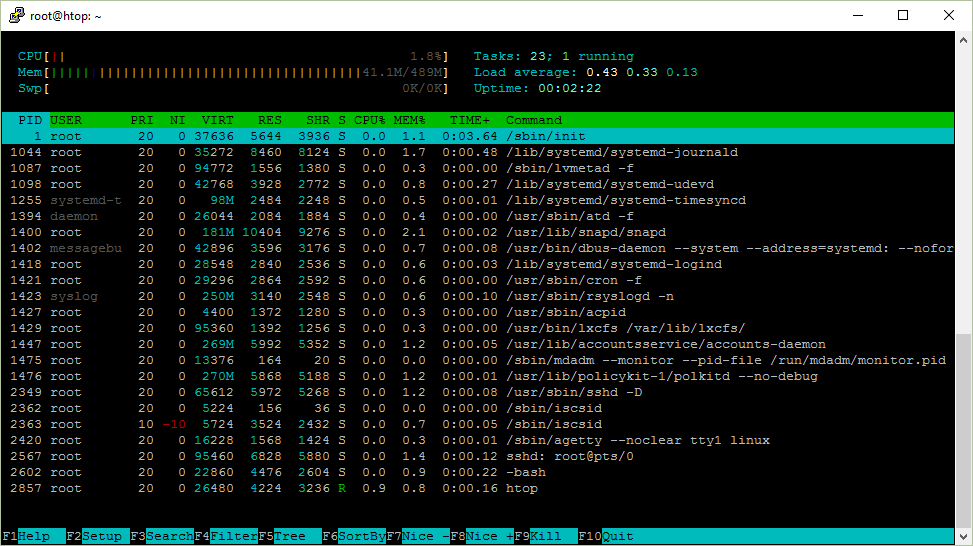
Uptime
L’uptime montre depuis combien de temps un système s’exécute.
Vous pouvez voir les mêmes informations en exécutant la commande uptime :
$ uptime 12:17:58 up 111 days, 31 min, 1 user, load average: 0.00, 0.01, 0.05
Comment le programme uptime sait-il cela ?
Il lit ces informations depuis le fichier /proc/uptime.
9592411.58 9566042.33
Le premier nombre est le nombre total de secondes pendant lequel le système s’exécute. Le second nombre est combien de secondes la machine a tourné au ralenti (idle). La seconde valeur peut être plus grande que l’uptime du système sur les systèmes avec de multiples coeurs puisqu’il s’agit d’une somme.
Comment l’ai-je su ? j’ai observé quels fichiers le programme uptime ouvrait lorsqu’on l’exécute. Nous pouvons utiliser l’outil strace pour cela.
$ strace uptimeIl va s’afficher beaucoup de choses. Nous pouvons utiliser grep pour l’appel système open. Mais cela ne marchera pas vraiment puisque strace redirige tout sur le flux de l’erreur standard (stderr). Nous pouvons rediriger stderr vers le flux de la sortie standard (stdout) avec 2>&1.
$ strace uptime 2>&1 | grep open
...
open("/proc/uptime", O_RDONLY) = 3
open("/var/run/utmp", O_RDONLY|O_CLOEXEC) = 4
open("/proc/loadavg", O_RDONLY) = 4
qui contient le fichier /proc/uptime que j’ai déjà mentionné.
Il se trouve que vous pouvez aussi utiliser strace -e open uptime et ne pas vous embêter avec grep.
Mais pourquoi avons-nous besoin du programme uptime si nous pouvons juste lire le contenu du fichier ? La sortie de la commande uptime est joliment formatée pour les humains tandis que le nombre de secondes est plus utile à réutiliser dans nos programmes ou scripts.
Premier partie en forme de mise en bouche, nous continuerons dans le second article de cette série par la notion de load average.

