











centralisé, décentralisé, P2P, mais c'est quoi tout ça ?
Une petite mise au point technique, parce que je vois qu'il y a beaucoup de confusion sur les termes « centralisé » (encore lui ça va), « décentralisé », « distribué », « fédéré », « pair à pair », etc.
Il faut dire que la confusion est assez normale, il n'y a pas vraiment de définition de ces termes, et ce que les gens entendent en les employant dépend de leurs lectures, leur compréhension, et leur sensibilité.
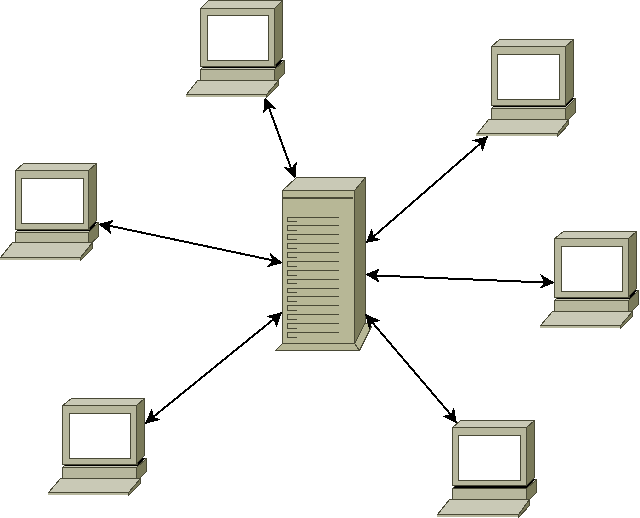
Commençons par le plus simple : centralisé. Un système centralisé c'est un système où tout le monde dépend d'une même autorité, un serveur a priori dans le cas informatique. Bien qu'un système centralisé soit beaucoup plus simple à faire sur le plan technique (facile de trouver des gens ou des informations quand ils sont tous au même endroit), il peut avoir ses propres problèmes : montée en charge en particulier ; il est plus difficile d'absorber des données quand il n'y a qu'un centre de traitement, les tuyaux peuvent rapidement se trouver trop petits, etc.
Un système de communication centralisé pose de nombreux problèmes : il est évident qu'il est plus facile d'espionner, censurer ou modifier des données quand elles sont dépendantes d'un seul point. Même sans intention malicieuse, on a un point unique de défaillance (ce que les anglophones appellent « single point of failure »), c.-à-d. qu'une panne, une attaque, une catastrophe naturelle ou pas provoque l'arrêt du service voire la perte des archives.
Dans les cas les plus gros, on prend un hangar et on le remplit d'ordinateurs, ce sont les fameux centres de données ou « data centers ».
Là où ça se complique un peu, c'est qu'un système centralisé peut être physiquement en plusieurs endroits, ou utiliser des systèmes de répartition/répétition des données. Le principe est d'éviter l'engorgement ou les risques de pannes cités plus haut, mais même si ces machines sont séparées et communiquent entre elles à distance, elles sont a priori toujours sous la même autorité.
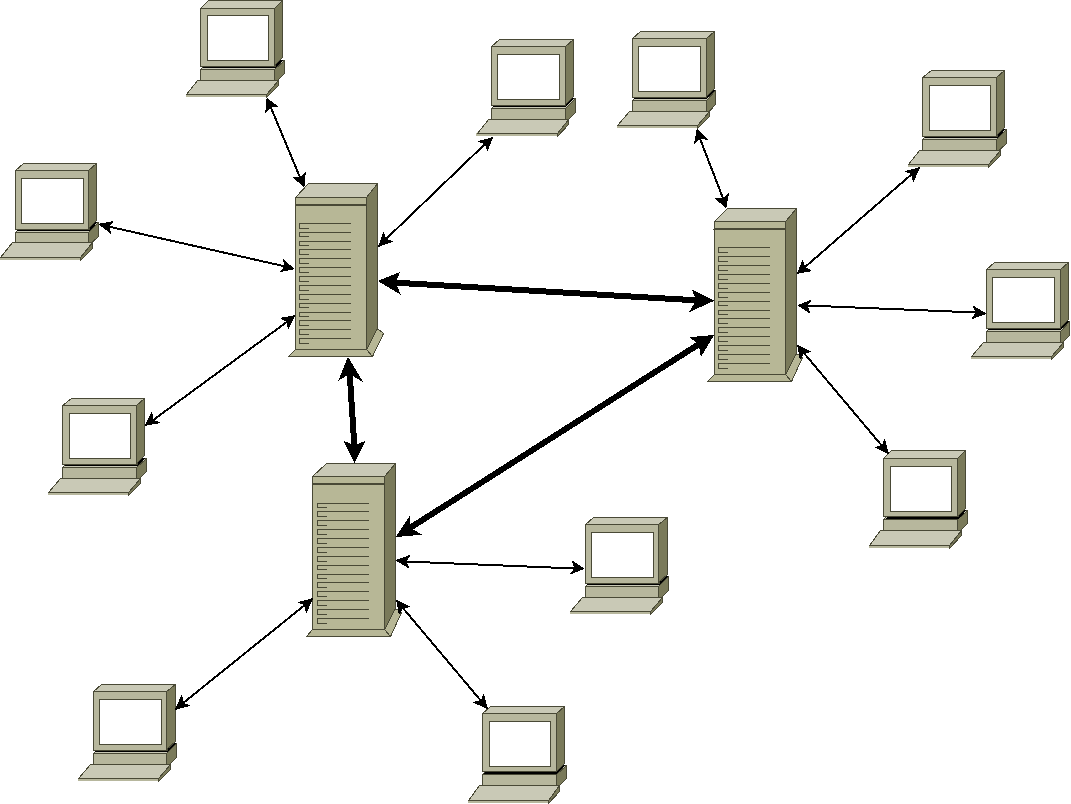
Passons maintenant aux systèmes décentralisés/distribués/fédérés. Certains vont pousser les haut-cris que je mette tout ça ensemble, parce qu'il n'y pas vraiment de définition et que chacun se fait plus ou moins la sienne.
« dé-centralisé » veut dire qui n'a pas de centre, ni plus ni moins. L'idée pour un système de communication, c'est que toute entité (individu, association, organisation, etc) puisse être une partie d'un réseau qui n'a pas d'autorité principale, et que ces autorités puissent parler entre elles.
On essaye ainsi d'éviter les problèmes de la centralisation, mais on se retrouve avec tout un tas de nouveaux problèmes, techniques pour la plupart : il est beaucoup plus difficile de retrouver des données ou des gens en plusieurs endroits, de se mettre d'accord sur la « langue » à utiliser pour communiquer (surtout quand on a des logiciels ou des versions d'un même logiciel différents), ou encore d'être sûr que la donnée qu'on a est à jour (est-ce que le message a été modifié ou supprimé ?).
« fédéré » est généralement employé pour parler de systèmes différents (noms de domaines différents par exemple, voire logiciels différents) qui peuvent communiquer entre eux. Un système décentralisé est fédéré par nature, sinon on a affaire à plusieurs systèmes centralisés indépendants. Disons que si on veut être pointilleux, on peut dire qu'un système décentralisé peut communiquer avec seulement certaines entités (je communique avec les serveurs de mon entreprise internationale, mais pas avec le reste du monde), et que la fédération implique l'idée que c'est ouvert à tous (ou presque, il y a souvent des gens qu'on ne veut pas, les spammeurs par exemple).
« distribué » ne devrait pas être employé pour les systèmes de communication. Le terme est normalement utilisé pour le calcul : si votre ordinateur a plusieurs processeurs, il distribue la charge de calcul entre eux, ou dans le cas de très grosses demandes (recherche par exemple), on peut demander à plusieurs machines distantes de faire chacun une partie d'une grosse opération mathématique. Dans ce cas, l'organisation de la répartition est souvent contrôlé par une même autorité (par exemple le laboratoire qui veut faire cette opération).
Par extension, le terme est aussi utilisé pour les systèmes de fichiers, et certains l'emploient pour les logiciels de communication, mais cela ne veut pas dire autre chose que décentralisé.
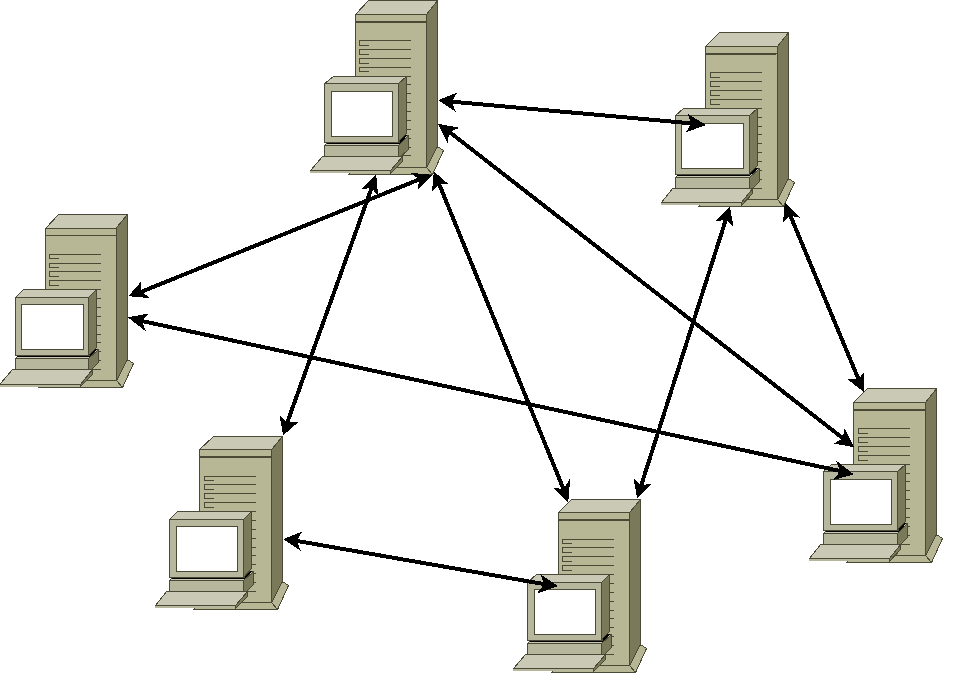
Enfin, il y a le terme P2P ou « pair à pair » (« peer to peer » en anglais). En fait une connexion pair à pair n'est rien d'autre qu'une connexion directe entre 2 ordinateurs, mais on l'associe souvent aux technologies plus ou moins apparentées qui ont commencé à apparaître à la fin des années 90/au début des années 2000 et qui servaient (et servent toujours) principalement à partager des fichiers.
Après Napster (lancé mi 1999) qui était un bête système centralisé qui mettait en relation des machines pour une connexion directe, il y a eu beaucoup d'essais et d'évolutions pour trouver un système qui permet de se passer de serveurs, l'idée étant principalement de permettre au réseau de fonctionner même si on lui coupe l'accès à une partie de lui-même.
Je vous passe toutes les techniques qui sont utilisées : c'est un domaine très pointu, très intéressant, et qui demanderait facilement un livre pour être expliqué. Ça part des systèmes de répartition par propagation de proche en proche à la Usenet, jusqu'aux récentes chaînes de blocs (blockchain), en passant par les tables de hachage distribuée (Distributed Hash Table), etc.
Ce qui fait principalement la différence entre un système « décentralisé » et « entièrement P2P », c'est la place du serveur. Un serveur, dans les grandes lignes, c'est ce qui permet à votre logiciel (le « client ») de contacter d'autres clients via d'autres serveurs. Il est là pour tout un tas de raisons : identifier les gens, donner les bonnes données aux bonnes personnes, garder
les fichiers à donner à un client actuellement hors ligne quand il sera disponible, etc.
Si on supprime le serveur, inévitablement c'est votre client (ou un autre) qui va devoir se charger de ce travail, ce qui aura un impact sur votre bande passante, la charge de travail pour votre processeur (et donc la durée de vie de votre batterie le cas échéant), et compliquera la tâche de votre logiciel (plus difficile de savoir à qui parler et à qui faire confiance quand on n'a pas de serveur comme référence).
Pour transformer un système décentralisé avec serveurs en système entièrement P2P (c.-à-d. sans serveur), je vais vous donner une recette : vous mettez un seul client sur votre serveur, et vous mettez le serveur et le client sur la même machine.
Bien sûr si vous voulez être vraiment indépendant, il va falloir supprimer le besoin de points de références, et en particulier le système de noms de domaine ou « Domain Name System ». C'est ce qui associe le nom de votre serveur (par exemple « libervia.org ») à l'adresse « IP » qui permet de vous retrouver sur Internet. Il va falloir aussi être capable de retrouver les données ou les gens un peu partout, et là on se retrouve avec les technologies intéressantes mais complexes évoquées plus haut (« D.H.T. », « Blockchain », « SuperPeer », etc).
Et XMPP dans tout ça ?
Je vais quand même parler un peu de XMPP. XMPP est un système dit « hybride », c'est à dire qu'il fonctionne normalement sur un modèle client/serveur, mais il peut faire du P2P à la demande (pour transférer un fichier ou faire de la visioconférence par exemple).
Il est même possible de fonctionner sans serveur sur un réseau local (comme expliqué ici), et il peut parfaitement devenir à terme un système entièrement P2P comme expliqué dans le paragraphe précédent.
Ceci dit, même si l'approche entièrement P2P est séduisante, je pense que l'architecture décentralisée sur un modèle client/serveur est un compromis bien plus efficace : elle limite le travail de votre client, permet une meilleure optimisation du trafic ou du calcul, et facilite l'échange asynchrone (quand deux personnes ne sont pas connectées en même temps). Bref, c'est tout sauf un modèle du passé comme on peut le lire parfois, et bien qu'il y ait plusieurs recherches et options intéressantes pour des systèmes entièrement P2P, il ne faudrait pas jeter le bébé avec l'eau du bain.

